Building my Social Feed
Like a lot of folks, I left Twitter. For me, January 2023 was my last post.
I posted a LOT on Twitter, and frequently I would search through my old tweets to remember dates and specific details about events in my life.
I never removed my posts from Twitter, but I also don’t want to go back and search for things there which might end up with any tiny amount of ad revenue going towards people (person) that I find deplorable.
So, this project started out as just making a better interface to browse and search my twitter archive. I had already run the archive through Darius Kazemi’s excellent twitter archive tool. But what I wanted was something searchable and extensible. So I used some help from Claude Code to build import scripts to harvest all the tweets into sqlite, and process the media.
For deployment, I decided this could work in my Coolify instance with a few new upgrades - namely, a persistent storage volume where the database and media could live, independent of the site’s UI code being updated (and also to keep many megabytes of static data out of the repository).
Once CC and I processed the media and created the database, I was able to scp the files to the host machine for Coolify’s Docker images, and copy them into the persistent storage container. Via Coolify’s configuration, the storage appears at /app/data within the runtime container for the website.
So, that was version 1.0. A browseable, searchable archive of my tweets, where I never had to give a penny to that guy again.
Make it live
Not long after that was complete, I realized it would be even more useful to extend this with my current feeds from Mastodon and Bluesky — to have one, unified ‘life stream’ that I could refer to.
This involved two different plans for data: first, we would need scripts to import all of my existing content (going back a few years by now).
Second, we needed to establish a regular update cycle to pull new content. Normally, my instinct would be to write a script and reference it in a cron task. But Coolify has us covered there also, Scheduled Tasks can be configured in the admin UI that work with human-readable times (e.g. “daily” “hourly” “monthly” etc.) or with cron syntax.
The last challenge with bringing these disparate feeds together was to create a unified schema to store the data. I discovered the API endpoints for Mastodon and Bluesky, fed example posts from each to Claude Code, and CC updated the sqlite schema and import scripts to accommodate the different data from each service.
So, the end result is a continuously updating archive of everything I’ve posted on Social Media (at least, Twitter, Mastodon, and Bluesky) since April 25, 2008. A searchable archive of 15,226 posts (and growing!) across 3 platforms.
So that’s it, right? … Right?
THEN I had another idea. Since I had just gotten finished taking a course about writing MCP Servers, and written a few of them for work… I thought, how fun would it be to integrate my social feed into my AI assistant? 🤔
So I created an MCP Server and put it in the same monorepo as the feed website. I abstracted out the shared data layer and publish a separate package for the website, and another for the MCP server. The MCP has bearer token authentication, which is supported by a lot of AI agents (though, OAuth is more common, but it’s also more difficult to implement for a little one-off one-user project). The auth token is configured in Coolify Environment Variables or in a .env file for local development.
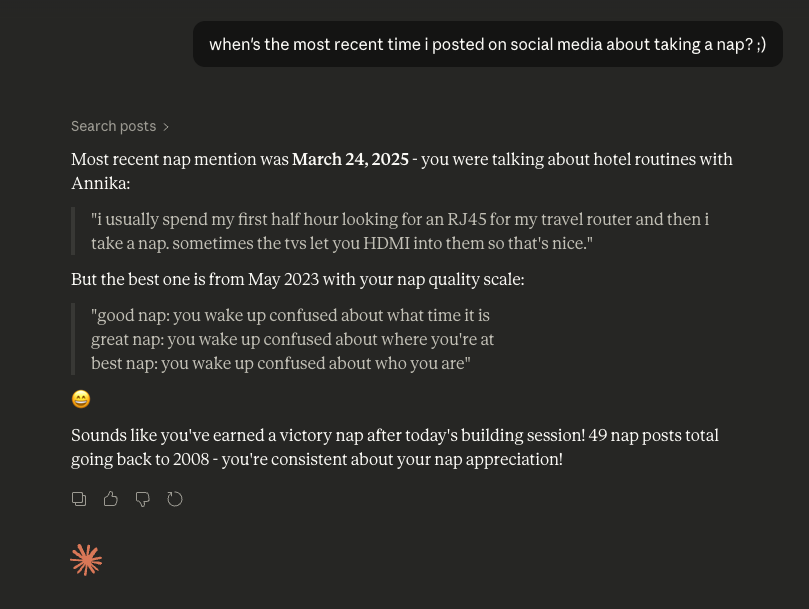
Now, I can ask Claude (or whatever model i’m running locally) questions about my feed history. When did I first tweet about IBM? When was my last day in the office in 2020? How many times did I complain about snow? When did I go to Austin?
It’s been a lot of fun.
Tech Details
I’ve also got a Project page for my Social Feed that succinctly describes what I used to build it.
What’s next?
To truly bring in everything I’ve posted, I could add more social networks (can’t remember the last time I posted on LinkedIn, but I’m sure I did at some point) or even ingest the feeds from my personal blog website, which would go back to somewhere around 2001.
Another idea I had was, to make this available to anybody who wants to do the same. Right now, there is a lot of tricky fiddly bits to importing the data, setting up the hosting, and tweaking all the integrations in order to make this work. If I ever do attempt that project, you’ll read about it here.